7614. Конкатенация
Знаменитый
программист Геннадий любит создавать новые слова. Одним из таких способов
является конкатенация существующих слов. Конкатенация означает записывать слово
сразу за другим. Например, если он имеет слова "cat" и
"dog", то может получить слово "catdog", что означает
название существа с одной кошачьей и одной собачьей головой.
От этого способа
создания новых слов Геннадию стало немного скучно, так что он изобрел другой
способ. Он берет непустой префикс первого слова, непустой суффикс второго слова
и присоединяет их. Например, если у него имеются слова "tree" и
"heap", то он может получить такие слова как "treap",
"tap" или "theap". Кто знает что они обозначают?
Геннадий
выбирает два слова и хочет знать, сколько различных слов он может создать,
используя свой новый метод. Конечно, будучи известным программистом, он уже
вычислил ответ. Можете ли вы сделать то же самое?
Вход. Две строки содержат слова выбранные Геннадием. Их длины
составляют от 1 до 100 000. Строки содержат только строчные буквы латинского
алфавита.
Выход. Выведите одно
число – количество различных слов, которое может создать Геннадий из имеющихся
слов.
|
Пример
входа 1 |
Пример
выхода 1 |
|
cat dog |
9 |
|
|
|
|
Пример
входа 2 |
Пример
выхода 2 |
|
tree heap |
14 |
РЕШЕНИЕ
комбинаторика
Анализ алгоритма
Пусть s1 и s2 – две входные строки. Строка s1 содержит |s1|
префиксов (например слово “cat” содержит префиксы “c”, “ca”, “cat”). Строка s2 содержит |s2| суффиксов (например слово
“dog” содержит суффиксы “g”, “og”, “dog”).
Если слова содержат
разные буквы, то любой префикс слова s1
можно соединить с любым суффиксом слова s2.
Таким образом получим |s1|
* |s2| слов.
Рассмотрим
случай, когда s1 и s2 имеют общую букву.
Рассмотрим слова “tree” и “heap”, у которых общая буква 'e' (для определенности
выберем третью букву в первом слове). Тогда слово “treap” можно получить двумя
методами склейки: “tre” + “ap” = “treap” или “tr” + “eap” = “treap”.

Таким образом
каждая пара одинаковых букв в s1
и s2 в будут порождать два
одинаковых слова. Остается вычислить количество пар одинаковых букв в s1 и s2 и вычесть его из |s1|
* |s2|. Отметим, что если
в паре одинаковых букв в первом слове эта буква стоит первой или во втором
слове последней, то одинаковых слов порождаться при склейке не будет (пустой
префикс в первом слове или пустой суффикс во втором слове при склейке не
допускается).
Если буква ‘i’ (‘a’ ≤ ‘i’ ≤ ‘z’)встречается в первом слове c1i
раз, а во втором слове c2i
раз, то при склейке сгенерируется c1i * c2i
одинаковых слов. Таким образом ответом к задаче будет число
|s1| * |s2| – 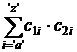
Реализация алгоритма
Входные строки читаем в массивы a и b. В x[i] подсчитываем количество букв с ASCII
кодом i которые встречаются в a, не считая первую букву. В y[i] подсчитываем количество букв с ASCII
кодом i которые встречаются в b, не считая последнюю букву.
#define MAX 256
#define MAXS 100010
int x[MAX], y[MAX];
char a[MAXS], b[MAXS];
Основная часть программы. Читаем входные строки и находим их длины.
gets(a); alen =
strlen(a);
gets(b); blen =
strlen(b);
Заполняем массивы x и y.
memset(x,0,sizeof(x));
memset(y,0,sizeof(y));
for(i = 1; i < alen; i++) x[a[i]]++;
for(i = 0; i < blen - 1; i++)
y[b[i]]++;
Вычисляем и выводим ответ.
res = 1LL * alen
* blen;
for (i = 'a';
i <= 'z'; i++)
res -= 1LL * x[i] * y[i];
printf("%lld\n",res);